State-of-the-art NLP benchmarks require interpretation of natural language that specifies conditions, procedures, and exceptions, often relying on implicit assumptions and external knowledge. Constructing complete semantic representations with proof-theoretic guarantees is…
Machine learning
13 Articles
13
Evaluating whether large language models (LLMs) capture the structure of natural language beyond local fluency remains an open challenge. Existing evaluation methods, largely based on task performance or short-context behavior,…
Large language models (LLMs) such as ChatGPT are increasingly used in the cultural heritage domain for tasks like metadata creation, semantic enrichment, and artwork captioning. Since these tasks depend on…
Mode collapse is a persistent challenge in generative modeling and appears in autoregressive text generation as behaviors ranging from explicit looping to gradual loss of diversity and premature trajectory convergence….
Heading Large language models (LLMs) have achieved remarkable progress in naturallanguage generation, yet they continue to display puzzling behaviors—such asrepetition and incoherence—even when exhibiting low perplexity. Thishighlights a key limitation…
This paper proposes formulating Zipf’s meaning-frequency law, the power law between word frequency and the number of meanings, as a relationship between word frequency and contextual diversity. The proposed formulation…
Clustering is a fundamental technique in machine learning and data mining, offering a powerful lens to understand self-organizing patterns in the real world. At its core, clustering is inherently information-theoretic:…
This paper shows a novel machine learning model for realized volatility (RV) prediction using a normalizing flow, an invertible neural network. Since RV is known to be skewed and have a…
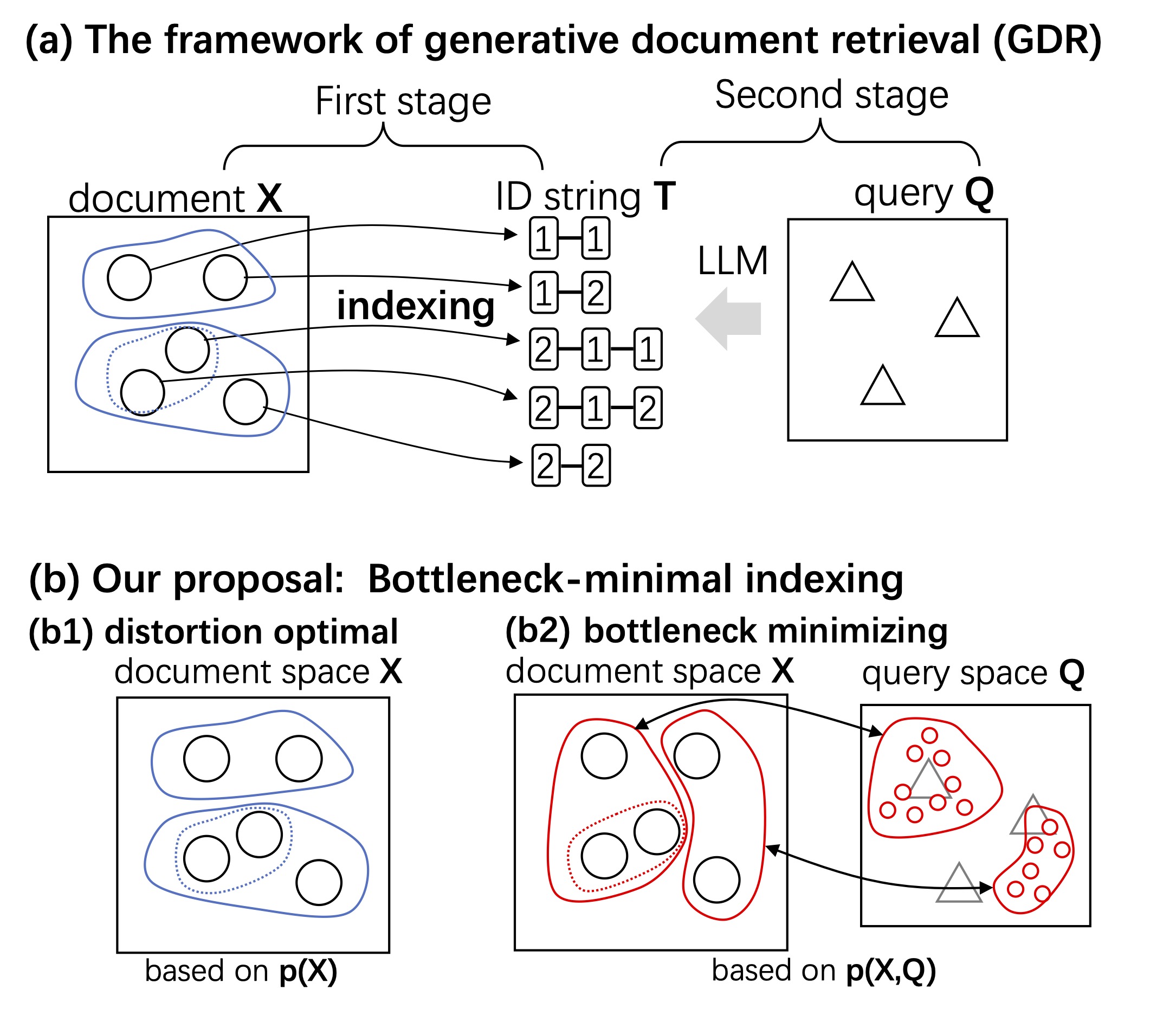
We apply an information-theoretic perspective to reconsider generative document retrieval (GDR), in which a document x∈X is indexed by t∈T, and a neural autoregressive model is trained to map queries Q to T. GDR…
Templates are multi-word expressions with slots, such as “Starting at _ on _ ” or “regard _ as _”, that appear frequently in text and also in data from sources…