Clustering is a fundamental technique in machine learning and data mining, offering a powerful lens to understand self-organizing patterns in the real world. At its core, clustering is inherently information-theoretic: it involves formulating the simplest possible hypothesis—how many clusters exist, and which document belongs to which cluster—while minimizing the information loss incurred during this assignment.
Over the past decade, clustering methods have shifted away from this information-theoretic foundation. Instead of modeling documents as probability distributions (e.g., word frequencies), recent approaches represent documents as dense vectors using powerful neural models like BERT. While effective, these vector representations lack a natural probabilistic interpretation, causing the information-theoretic perspective to fade into the background.
In this research, we revisit and revitalize the classic information-theoretic view by leveraging generative language models. Specifically, we use the Doc2Query model to represent each document as a probability distribution over all possible generated texts. Although this space is infinite and discrete, we estimate the relevant distributions and their KL divergences using regularized importance sampling.
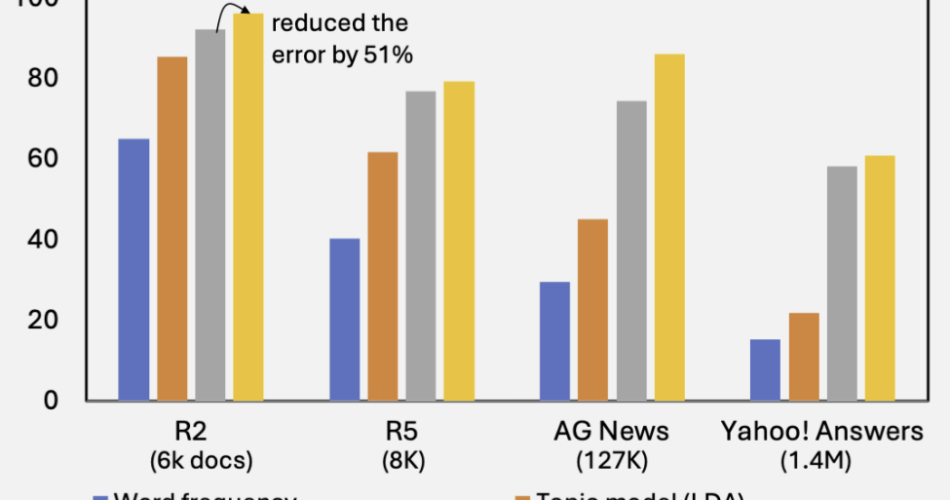
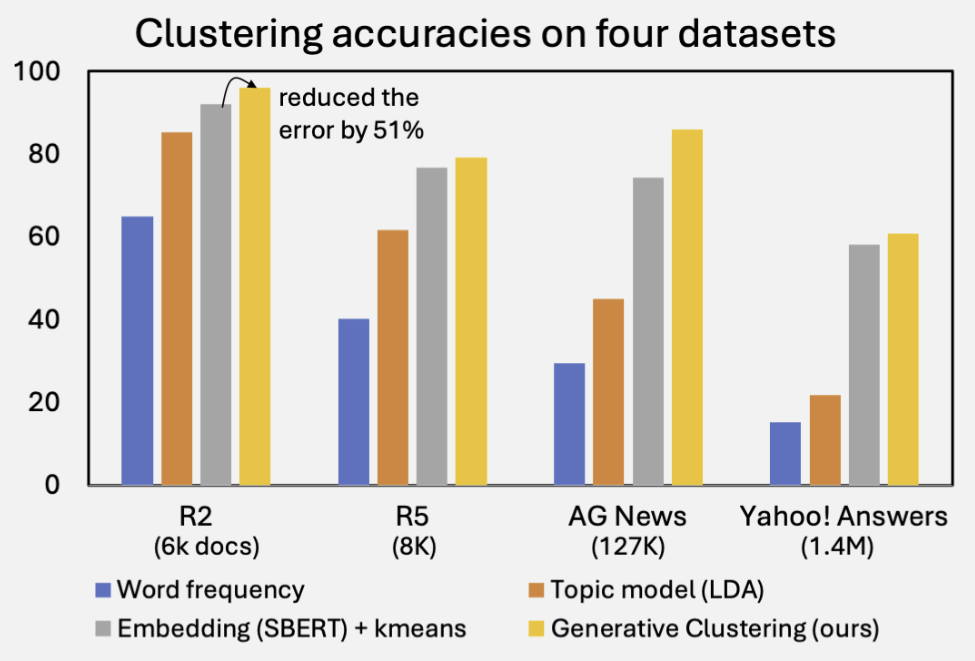
In essence, our method performs clustering and statistical estimation hand in hand. The results are striking: across four standard document clustering benchmarks, our method consistently outperforms strong embedding-based baselines—often by a significant margin.
References
- Xin Du and Kumiko Tanaka-Ishii. Information-Theoretical Generative Clustering of Documents. In Proceedings of AAAI, 2025. [link]