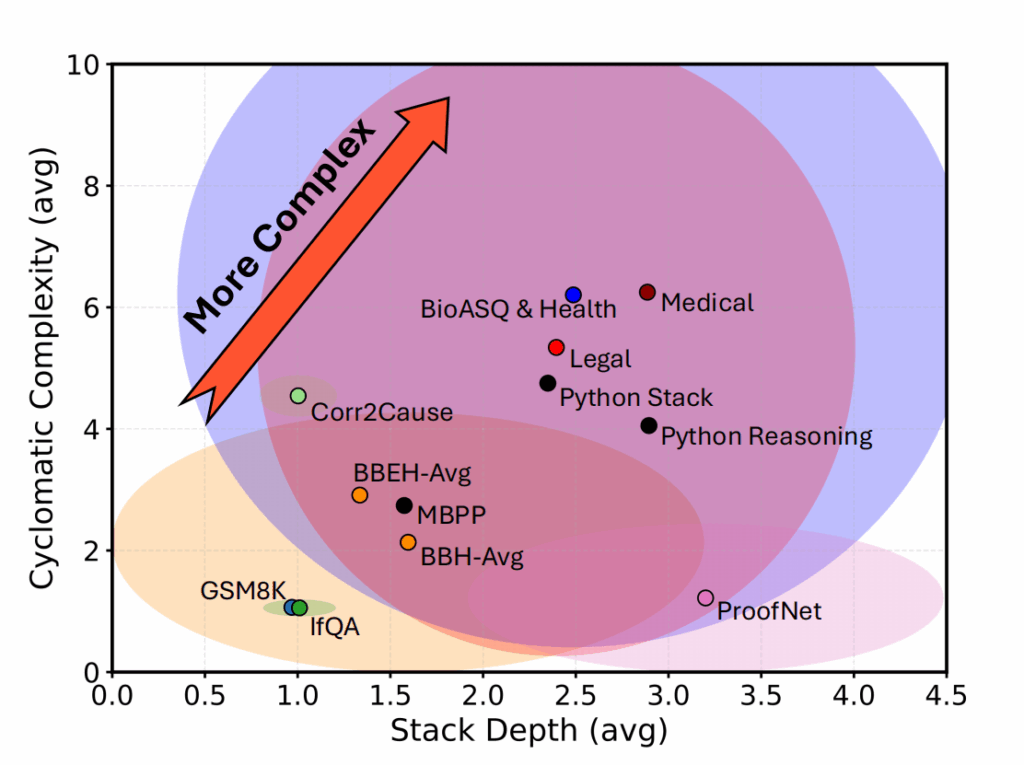
State-of-the-art NLP benchmarks require interpretation of natural language that specifies conditions, procedures, and exceptions, often relying on implicit assumptions and external knowledge. Constructing complete semantic representations with proof-theoretic guarantees is frequently impractical at scale, and purely text-based reasoning offers limited means of inspection. This paper asks how much understanding of benchmark language can be achieved when formal semantic guarantees are weakened.
We investigate this question by extracting computables: executable representations whose runtime behavior provides operational evidence of semantic adequacy, including executability, execution traces, and runtime failures. We induce and iteratively refine computables for benchmark instances using retrieval from external knowledge. Across mathematical reasoning, multi-step reasoning, causal inference, and rule- and exception-heavy legal and biomedical benchmarks, we find that the proposed approach consistently exceeds text-only reasoning and one-shot code execution. Beyond accuracy, our analyses show that these computables provide scalable, inspectable semantic evidence: they expose conditions and exceptions benchmark language forces into executable form, offering a practical bridge between proof-oriented semantics and purely textual reasoning.
References
Haoyang Chen and Kumiko Tanaka-Ishii. Understanding Benchmark Language Under Weakened Formal Semantics. Transactions of the Association for Computational Linguistics (TACL), in press, to appear in 2026.