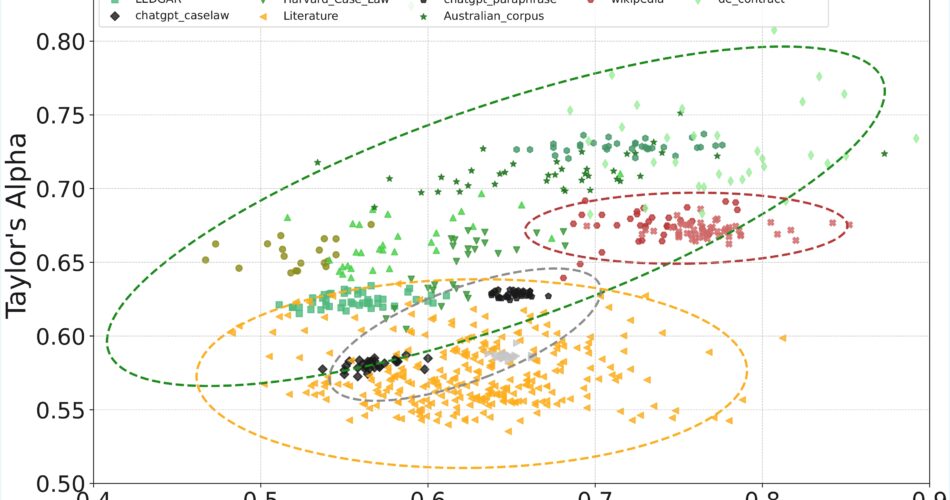
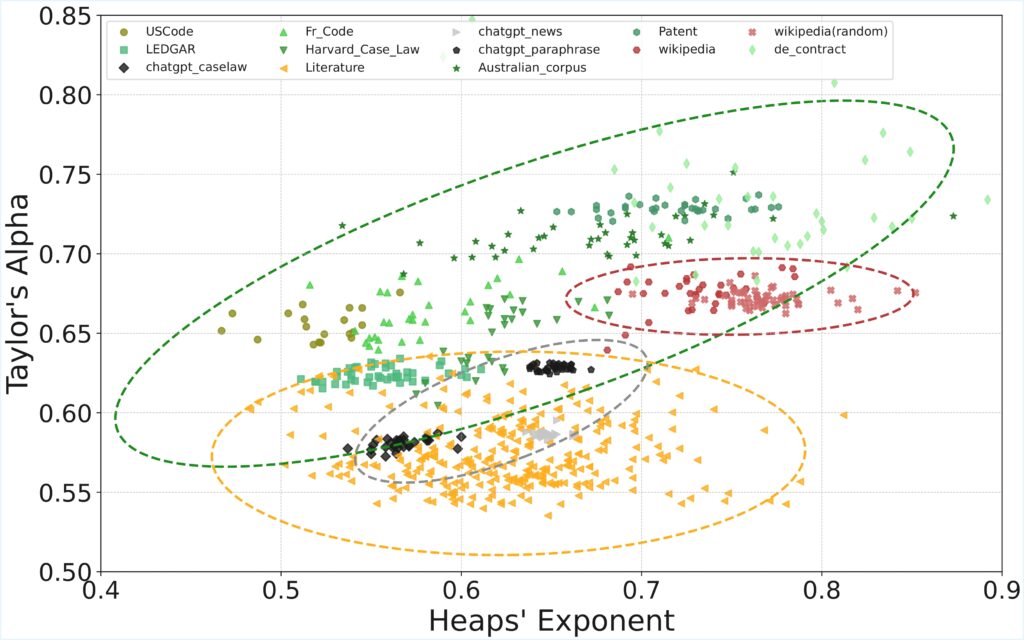
This work presents a comparative analysis of text complexity across domains using scale-free metrics. We quantify linguistic complexity via Heaps’ exponent β (vocabulary growth), Taylor’s exponent α (word-frequency fluctuation scaling), compression rate r (redundancy), and entropy. Our corpora span three domains: legal documents (statutes, cases, deeds) as a specialized domain, general natural language texts (literature, Wikipedia), and AI-generated (GPT) text. We find that legal texts exhibit slower vocabulary growth (lower $\beta$) and higher term consistency (higher α) than general texts. Within legal domain, statutory codes have the lowest β and highest α, reflecting strict drafting conventions, while cases and deeds show higher β and lowerα. In contrast, GPT-generated text shows the statistics more aligning with general language patterns. These results demonstrate that legal texts exhibit domain-specific structures and complexities, which current generative models do not fully replicate.
References
Haoyang Chen and Kumiko Tanaka-Ishii. 2025. Scale-Free Characteristics of Multilingual Legal Texts and the Limitations of LLMs. In Text, Speech, and Dialogue: 28th International Conference, TSD 2025, Erlangen, Germany, August 25–28, 2025, Proceedings, Part II. Springer-Verlag, Berlin, Heidelberg, 102–114. [link]