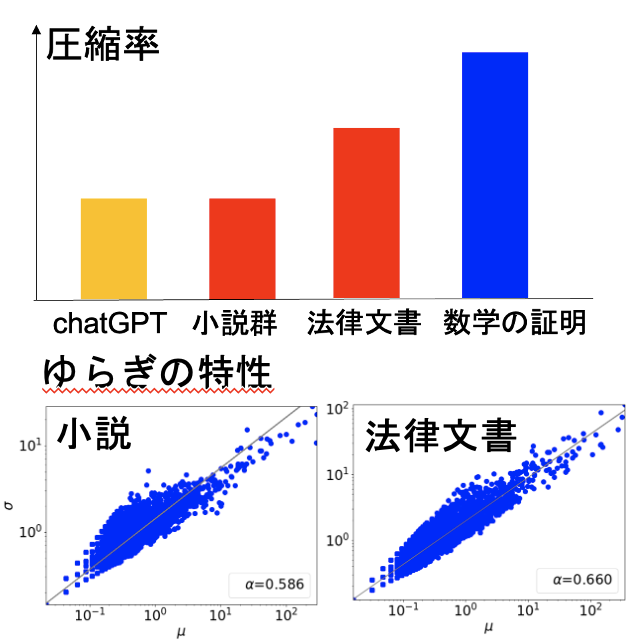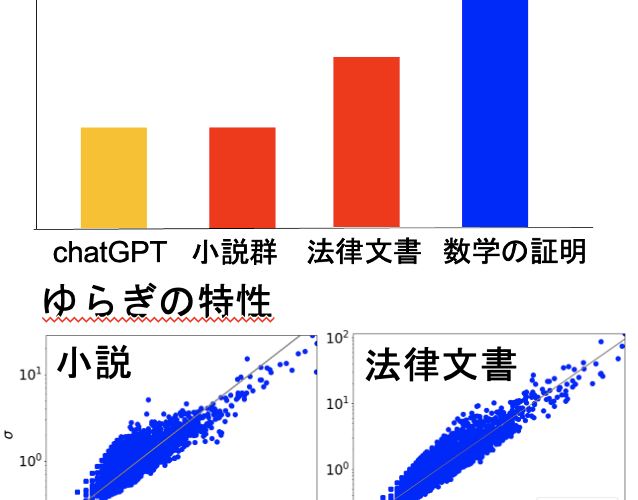
Documents have complexity from various perspectives, such as compression rate and the degree of fluctuation. The complexity varies depending on the extent to which the document is based on “inference.” For example, a corpus of mathematical proofs has a higher compression rate than literary works. Even within natural language documents, those based on inference, such as legal documents, have properties similar to mathematical proofs. We are investigating the relationship between the degree of inference and complexity, considering the language models necessary for legal documents and software engineering.